
The Last Interface
The race is not for better models, but for better understanding: personal intelligence, trust, and the rails of the next economy


By 2030, AI agents will mediate trillions of dollars in commerce, fundamentally restructuring how consumers discover, evaluate, and purchase. The protocols for this transition are being written now. Missing from the current buildout is the capability that determines whether agents become genuine representatives or remain sophisticated tools: the integrated understanding of a whole person that this paper terms epistemic completeness.
The implications reshape four domains. Personal assistants shift from response engines to representation systems. Agentic commerce shifts “rails” upstream into identity, trust, and personalization, creating shopping experiences that can actually feel unique again. Brand equity either becomes portable into agent-mediated channels or collapses into interchangeable specifications. Advertising either remains surveillance-driven interruption or becomes relevance-driven service, making much of today’s privacy theater and data middlemen structurally unnecessary.
The infrastructure layer for the agentic economy remains unoccupied. Whoever supplies it captures a durable position: the standard layer through which intent is expressed, evaluated, governed, and executed as commerce shifts into agent-native channels.
This paper argues that outcome is structurally inevitable. It is framed through two architectures I developed over nearly a decade: LUCID, a federated reasoning layer for institutions, and OPAL, a sovereignty-preserving architecture for personal agents. Both are summarized at the conclusion.
What makes this outcome inevitable is not desire, foresight, or optimism. It’s structural constraint. The agentic promise is genuine representation, which requires cross-domain understanding. That understanding is irreducibly fragmented across institutions that cannot legally, competitively, or politically aggregate it. Direct centralization fails on privacy, antitrust, and trust simultaneously. Model improvement alone cannot bridge missing signal. As agents become the primary interface for commerce, coordination, and decision-making, the system is forced toward architectures that allow inference to compound across boundaries without collapsing ownership or control. Federation is not one possible solution among many. Under these constraints, it is the only class of solution that can scale.
I. The Race
There is a moment in every technological transition when the pieces on the board become visible before the game is decided. The infrastructure is being built. The protocols are being written. The investments are being made. But the question of who will occupy the commanding position remains genuinely open. We are in such a moment now.
The transition is from artificial intelligence as a tool to artificial intelligence as an agent: software that does not merely respond to queries but acts on behalf of humans across the full complexity of digital life. Not a chat surface that answers questions, but a representative that negotiates, coordinates, purchases, schedules, decides and acts. Not an assistant that waits for instructions, but a cognitive extension that understands your constraints, anticipates your needs, and handles the friction of modern existence so you do not have to. This requires something no current system possesses: epistemic completeness, the integrated understanding of a whole person that makes genuine representation possible.
The economic magnitude is staggering. McKinsey projects one to five trillion dollars in global retail revenue will flow through agentic channels by 2030. AI-driven retail sales increased 1,200% between June 2024 and February 2025. Google has assembled 60 organizations to establish protocols for agent-mediated transactions. Anthropic’s Model Context Protocol now operates under Linux Foundation governance with nearly one hundred million monthly SDK downloads. Stripe has moved its Agentic Commerce Protocol and Suite into production. Apple is rebuilding Siri around large language models. OpenAI processes commerce with over a million merchants. The race has started, and it is moving faster than most observers recognize.
Bill Gates, in a formulation that merits careful attention, observed that whoever wins the personal agent “wins the big thing,” because “you will never go to a search site again, you will never go to a productivity site, you’ll never go to Amazon again.” The statement sounds hyperbolic until one examines its structural logic. If an agent lives up to its promise, if it genuinely comprehends your preferences and constraints, your patterns and priorities, your relationships and responsibilities, then every digital interaction becomes a conversation with that agent rather than direct engagement with underlying services. The interface dissolves. Only the outcome remains.
Yet there is a problem at the center of this vision that current development has not resolved. The protocols define how agents will communicate, authenticate, and transact. They do not define how an agent learns a principal deeply enough to represent them faithfully when goals conflict, budgets tighten, deadlines loom, or tradeoffs become painful. Current development treats understanding as an emergent byproduct of better models and more tools. It is not. Without an explicit architecture for personal context, agents will remain capable and frequently correct, but unfaithful representatives.
I have spent nearly a decade on this problem. First as a researcher exploring personal intelligence architectures. Then as a founder who raised thirty million dollars to build infrastructure for personal AI. Most recently as someone who concluded that the solution requires assets I did not possess: the scale and trust relationships of a major platform. Before that, I built and sold a design consultancy to Salesforce, an experience that taught me something essential: the most profound technical capabilities fail if they cannot be experienced. This is as much a design problem as an engineering problem.
That work produced the frameworks introduced at the end of this paper. But first: why the problem is so hard, and why current approaches cannot solve it.
II. The Gap
The distinction between capability and understanding illuminates why the personal agent problem has proven so resistant despite extraordinary advances in AI.
Modern language models process natural language with remarkable sophistication. They can reason, write, code, and converse with what feels like genuine intelligence. Yet they know almost nothing about the specific humans they serve. Every conversation begins from zero at worst or siloed memory at best. The model that helps you cannot remember that you are vegetarian, that you have a daughter starting college next fall, that you prefer direct communication, or that you are price-sensitive on electronics but will pay a premium for travel. Google’s AI can pass the bar exam, but Google Assistant cannot remember that you are lactose intolerant.
The evidence of this failure surrounds us. Amazon invested over twenty-five billion dollars in Alexa between 2017 and 2021, achieving deployment in hundreds of millions of households. The result, according to internal assessments, was an expensive timer. Apple’s Siri has operated for fifteen years with access to the most integrated hardware-software ecosystem in consumer technology. The promised personalized Siri with genuine contextual understanding has been delayed to 2026. Microsoft discontinued Cortana entirely. One in three voice assistant requests results in error. The gap between promise and delivery is not narrowing: it is widening as AI capabilities advance while personal assistants remain stuck in patterns established a decade ago. We are closer to flying cars than we are to a genuine personal assistant.
Consider what epistemic completeness actually requires. An agent advising on purchases must understand your finances, your values, your aspirations, and the complex ways these interact. An agent representing you to a luxury brand must know your taste, your history with that brand, your willingness to pay for craftsmanship versus your skepticism of markup. An agent negotiating on your behalf must comprehend your priorities, your constraints, your walkaway points. Information retrieval cannot solve this. Only understanding can: the kind that emerges from sustained attention to a whole life.
Consider what happens when you search for a flight. You go to Expedia and search “JFK to LAX, under $500.” In that moment, you are subconsciously filtering through hundreds of pieces of metadata: the airline that lost your bag twice, the terminal you hate at LAX, your preference for morning departures, your willingness to connect through Denver but not Phoenix, your height that makes extra legroom worth $50 but not $100, the loyalty program you are three flights from status on, the colleague who mentioned a hotel near the conference venue. You process all of this instantly, invisibly, and apply it to every result. Now give that same query to ChatGPT. It can execute the search. It can find flights under $500. But without access to the accumulated context of your travel history, preferences, annoyances, and aspirations, it will return results that are technically correct, but no more correct than Expedia, and practically less valuable because we lose the adjacent features that Expedia offered. The task is technically completed. The job is not done in terms of the promise AI is making. This is the gap between capability and epistemic completeness: the difference between an agent that can act and one that can represent.
The objection is obvious: no system can capture every memory, preference, and quirk that constitutes a human life. This is correct, and it misses the point. Epistemic completeness does not require omniscient data collection. It requires federating enough previously disparate signals that a sufficiently sophisticated model can infer the rest. This is the role of what I call the Personal Adaptive Model, or PAM: a unique model instance trained specifically on you.
A PAM is not a profile or a preference file. It is a living intelligence that learns continuously from your behavior, adapts to your evolving circumstances, and trains on the patterns that make you distinct from every other human. Feed it your travel history, your purchase behavior, your browsing patterns, and your communication style, and it begins to infer the preferences you never explicitly stated. It notices that you switched to aisle seats after that brutal middle-seat transatlantic. It recognizes that you avoid certain airlines without being told why. Given sufficient signal across sufficient domains, your PAM does not merely recall what you have done. It understands who you are.
At maturity, it may understand you better than you understand yourself. It can anticipate needs you have not articulated because it sees precursors across domains. It does not require omniscience. It requires enough cross-domain signal to infer reliably, and enough governance to ensure those inferences serve the principal rather than the platform.
III. The Blind Spot
If epistemic completeness is the goal, fragmentation is the obstacle. The data required to understand a whole person is distributed across organizations that have no mechanism to share it, and every incentive not to.
A user’s digital life scatters across 60 to 90 applications. Financial behavior lives with banks and payment networks. Location patterns live in maps and ride-sharing services. Communication patterns rest in email and messaging platforms. Purchase history fragments across merchants. Health data sits with insurers, providers, and fitness trackers. Each repository holds a dimension of your life. None holds enough dimensions to compose the whole.
This is not accidental. It is the residue of how the internet developed: application by application, silo by silo, each company building walls around its data because data was the asset. Data was the moat. Data was the justification for valuation. The result is an economy of partial vision. Every organization sees a sliver. None sees the whole.
The consequences are everywhere. Netflix has spent billions on recommendation algorithms. They still cannot know that you binged a cooking show because you were sick in bed and bored, not because you developed a sudden passion for French cuisine. They cannot know what you watched on Apple TV last night, or that you just booked a trip to Lyon, or that your anniversary is next week. Any of these signals would transform their recommendations. All of them live somewhere Netflix cannot see.
Spotify knows your music. Peloton knows your workouts. Neither knows both, which means neither can build the playlist that actually matches your training intensity. Amazon knows your purchases. Google knows your searches. Neither knows the other, which means neither understands the gap between what you research and what you buy. Your bank knows your salary. LinkedIn knows your career ambitions. Neither knows both, which means neither can advise on whether this is the year to negotiate or wait.
The fragmentation creates a ceiling that no amount of AI capability can break through. You can build the most sophisticated model in the world, but if it only sees one dimension of a person, it will only understand one dimension. Capability without signal is intelligence without wisdom.
The obvious question is why no one has aggregated these signals. Historically, the answer is leverage. Data was the moat, and sharing meant surrendering. That created a prisoners’ dilemma at ecosystem scale: everyone would benefit from pooled intelligence, but no one moves first because the first mover loses defensibility while gaining little in return. Federation changes the payoff matrix. It shifts cooperation from “share data or lose” to “share interfaces and gain,” because contribution can improve outcomes without exposing the underlying asset.
Acquisitions have not solved this. When Facebook bought WhatsApp and Instagram, it did not achieve epistemic completeness. It achieved three silos under one roof. When Google bought Fitbit, it did not suddenly understand its users as whole people. It added one more partial signal to a collection of partial signals. The corporate structure that enables acquisition is the same structure that prevents integration: business units protect their data because data is how they justify their existence.
The incumbents are trapped. They cannot unilaterally open their data without competitive suicide. They cannot bilaterally share without antitrust scrutiny. They cannot acquire their way to completeness because acquisitions preserve the very silos they were meant to dissolve. The only path forward is an architecture that enables intelligence to flow while raw data stays proprietary and safe.
IV. The Architecture
The answer is federation. In a federated architecture, computation moves to the data, learns locally, and returns only constrained inference signals or model updates, not the underlying records. Intelligence can compound across domains while raw personal data remains protected at its source.
Google’s federated learning infrastructure improves keyboard predictions across billions of devices without centralizing what anyone types. The model updates travel; the keystrokes never leave the phone. Apple applies similar architectures for photo recognition, voice adaptation, and predictive text. Flower Labs runs federated training across fifteen million devices in production. The mathematical foundations have matured from academic concepts into engineering practice. Federation works. The question is no longer whether it is possible but who will build the version that matters.
The digital advertising industry has been proving out federation in its own crude way for twenty-five years. Ad networks, data exchanges, demand-side platforms, data management platforms: this entire Rube Goldberg apparatus exists precisely because no single company possesses enough signal to target effectively alone. The ecosystem is a jury-rigged solution to the fragmentation problem, built on surveillance because privacy-preserving alternatives did not exist when the architecture calcified. They exist now. The industry spent two decades building surveillance infrastructure to solve a problem that federation solves better.
The skeptic’s objection is predictable: competitors will never cooperate. Netflix will never help Prime Video. This objection assumes the old model where sharing means surrendering. Under federated inference, no one shares raw, personal or proprietary data. Netflix encodes behavioral patterns as mathematical embeddings. Prime Video encodes its own. These representations flow not to each other but into the user’s Personal Adaptive Model, which synthesizes understanding inside a cryptographically secured enclave. Netflix never sees Prime Video’s patterns. Prime Video never sees Netflix’s. Neither sees the synthesized result. Only the PAM does, and the PAM works for the user. And that PAM only returns those insights cryptographically to an agent acting on the user’s behalf.
This is the critical architectural insight: even the receiving party never touches the data. The embeddings inject directly into the agent. Companies contribute to an intelligence layer they themselves cannot access. They benefit from the improved understanding that PAM-equipped users bring back to their platforms, but they never see what other sources contributed to that understanding. The architecture makes cooperation rational where it was previously suicidal.
Consider what this enables. A travel company encodes patterns about a user’s trip planning behavior. A streaming service encodes patterns about that user’s entertainment preferences. A financial service encodes patterns about her spending capacity and risk tolerance. None sees the others’ contributions. But the PAM, drawing inference across all three inside its secure enclave, can assemble understanding that no single source could achieve: this user is planning a trip, prefers boutique experiences over chains, and has budget for a premium option. The cross-domain synthesis reveals what single-domain analysis cannot. Federated intelligence is worth more than the sum of its parts because inference across boundaries surfaces patterns that no single boundary contains.
Federation is not utopian. It is inevitable. The alternative is permanent fragmentation: a world where personal AI remains a collection of disconnected tools, each brilliant in isolation, each useless for genuine representation. This may have been an acceptable standard in the legacy web, it will not be in the agentic world. Every organization that wants to offer real personalization will eventually face the same choice: federate or fall behind. The only question is whether they help design the architecture or inherit one designed without them.
The federated architecture provides a reasoning layer where participants contribute knowledge through mathematical embeddings rather than raw data, where Personal Adaptive Models learn inside cryptographically secured enclaves, where a Universal Inference Oracle provides structured access to intelligence without exposing underlying signals. The network enables understanding to compound across domains while ensuring no participant gains access to another’s protected information. Privacy becomes structural rather than policy-based: a property of how computation occurs rather than a promise requiring trust.
The security foundations require honesty about their current limitations. Trusted execution environments have proven vulnerable: researchers have extracted encryption keys from production SGX deployments through side-channel attacks. Homomorphic encryption remains computationally expensive for complex operations. Differential privacy introduces noise that degrades utility at aggressive epsilon values. These are engineering constraints, not theoretical barriers. Apple’s Private Cloud Compute demonstrates production-grade privacy-preserving computation: formal verification, transparency mechanisms, cryptographic attestation at every layer. The technical trajectory points toward solutions. The engineering discipline must match the ambition.
A note on what “contribute” means in this paper: it does not mean companies send data into a shared pool. It means services support authenticated agent interaction and publish machine-readable offerings and policies, while learning and synthesis remain local to the user’s personal model.
V. The Brand Experience
Agentic commerce threatens to destroy brand equity as a competitive asset.
Brands have built something valuable over decades. The luxury retailer’s immersive environment. The airline’s loyalty architecture. The hotel’s sensory vocabulary of welcome. These are not decorations, but rather moats, accumulated investments in experiential differentiation that justify margin premiums and resist commoditization.
When an AI agent handles discovery and purchase, the consumer never enters the brand environment at all. They interact with a chat interface that strips away everything the brand has built. The agent sees specifications and reviews. It does not feel the weight of a well-made object or the warmth of attentive service. The transaction completes but the relationship never forms.
This pattern has precedent. Amazon reviews collapsed brand differentiation for commodity goods. A generation of direct-to-consumer companies discovered that when the interface controls discovery, the interface captures the margin. Agentic commerce does to experiential brands what Amazon did to commodities: it reduces differentiation to data.
The numbers make the threat concrete. If one trillion dollars flows through agent channels by 2030, brands that cannot express themselves through those channels compete for a shrinking share of direct human attention. Luxury, hospitality, non-commodity retail, direct-to-consumer: every category where experience justifies margin faces a future where the experience layer that justifies their pricing simply does not render.
The executives responsible for brand equity see this clearly, even if they do not yet see a solution. Their brand is their moat. The agent economy threatens to drain it.
The emerging protocol layer (ACP, UCP, etc.) addresses some concerns, but it does not solve the core brand problem. Most protocols focus on execution and accountability: who is the merchant of record, who fulfills, who handles returns, who owns the service relationship. That is necessary, but it is not sufficient. Brands will not participate at scale unless they can control representation, protect price integrity, and preserve post-purchase accountability across agentic surfaces, not only at checkout.
Federated architecture addresses this through what might be called federated brand intelligence. The same infrastructure that lets organizations supply behavioral understanding without exposing personal data can also let brands publish experiential identity: their visual language, voice, values, and interaction grammar, packaged as standards and primitives that generative systems can express on any agentic surface.
The interface layer matters as much as the data layer. Current agent interactions occur through generic chat surfaces: text in, text out. But generative UI changes this entirely. Systems like A2UI (Agent-to-User-Interface) enable agents to dynamically generate visual interfaces tailored to context, user, and task. The agent does not describe a product in text. It renders a shopping experience: images, layouts, interactive elements, purchase flows, all generated in real time.
This is where brand identity can live in the agentic era. When a consumer’s agent interacts with a brand through this proposed architecture, the brand can make available not just product data but design primitives: assets, voice, color systems, typography, spatial relationships, and interaction patterns, delivered through merchant-controlled interfaces. The generative interface assembles these primitives into a surface that carries the brand’s essence while adapting to the individual consumer’s preferences and context. The user experiences something that feels like the brand, or a collection of brands, rendered in a format optimized for them.
Consider what this enables. A consumer opens a shopping interface, and it generates specifically for them: products arranged in their aesthetic, presented in their preferred format, priced within their constraints, all while maintaining the visual identity of the brands being presented. The PAM knows their style from cross-domain patterns. Brands that provide experiential identity primitives to the federated layer earn weighted visibility and faithful representation. Brand equity becomes a dynamic relationship renewed through every interaction, not a static asset eroding with each agent-mediated transaction.
This is the difference between an ecosystem brands will embrace and one they will resist. Current protocols preserve customer relationships but not experiential identity. The architecture described here preserves both. The choice for brand-dependent businesses is not whether to participate in agentic commerce. It is whether that participation occurs through infrastructure that protects what they have built, or infrastructure that strips it away.
VI. The Advertising Inversion
The surveillance advertising model is already strained, and its failure mode is now cultural as much as technical. The ecosystem depends on intrusion, identity resolution, and measurement proxies that few participants fully trust. That system can persist, but it is poorly matched to agent-native interfaces, where the user expects representation, not persuasion.
And still, most ads miss. The click is the rare exception, not the rule. The system is optimized for reach, frequency, and measurement theater, not for genuine relevance.
Agentic AI could break this pattern entirely.
It could have been the moment advertising stopped being something done to users and became something done for them. A personal agent should represent a principal. It should optimize for the person’s interests, constraints, and intent, not for a bidder’s budget. Personal AI should be an impenetrable boundary between consumers and persuasion, permitting commerce only on the user’s terms.
So it is worth noticing what we are choosing to build.
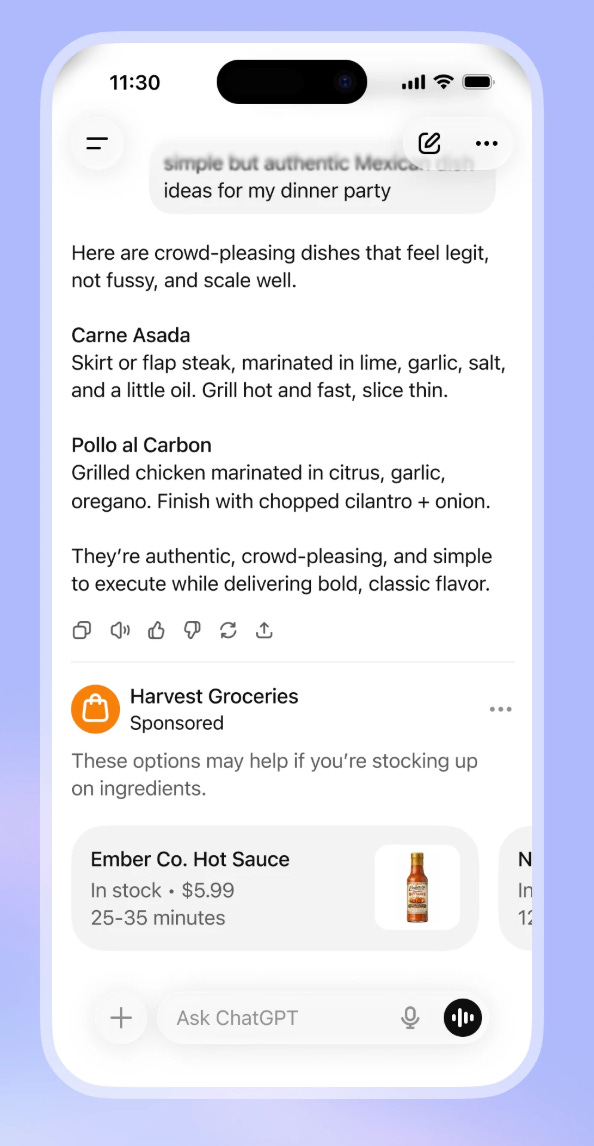
OpenAI’s announced direction for ChatGPT ads is familiar: sponsored placements appended to responses, labeled as ads, with controls to dismiss and tune personalization. “Intelligence” is framed as contextual mapping inside the same old arrangement. The ad is still an interruption. The user is still the surface. The advertiser is still the economic customer.
This is not a moral failure. It is a strategic choice. And it gives us what we have had, not what we could have.
In the real world, we routinely accept intermediaries who “sell” us things, because the relationship is legible and bounded. A sommelier is paid to move wine, but their job is still to help you choose well. A great salesperson succeeds by aligning an offering with a buyer’s real needs. We even volunteer personal context to make the experience better: dietary restrictions, past purchases, preferences, budget, the occasion. We tolerate the incentive because we can feel whether the guidance is serving us.
Personal AI can replicate the best version of that dynamic, without importing the surveillance apparatus that has made digital advertising so corrosive.
The shift is simple: move from probabilistic targeting to deterministic matching.
A user’s agent expresses a need as it arises in conversation, in the user’s own language, shaped by the user’s real constraints. Brands do not chase the user across the internet. They publish machine-readable offerings: catalogs, policies, eligibility rules, fulfillment constraints, and economics. The match happens inside the user’s Personal Adaptive Model. No personal data needs to leave the user’s control. No tracking is required. A brand learns who matched only if a transaction follows, or if the user explicitly chooses to engage.
Your model knows you need running shoes, not because a pixel trailed you across the web, but because it understands you are training for a marathon, your current shoes are nearing replacement mileage, and your training load is rising. Or because you asked, plainly, for recommendations. A brand that sells running shoes has made its inventory and policies available in a federated layer in a merchant-controlled way. Your PAM surfaces the option because it genuinely serves your interests. That is not targeting. That is service.
The economic model inverts.
Brands do not pay to interrupt. They pay to be discoverable by agents actively working on behalf of users. Users become the customer. The system’s job is to represent the user’s intent, not to harvest the user’s attention.
Once you do this, the surveillance stack becomes structurally unnecessary. Identity resolution as an advertising primitive matters far less when matching occurs locally and disclosure is conditional. Walled gardens lose the moral and economic leverage of hoarding data when the most valuable context lives with the user and is deployed only when the user wants an outcome.
Historically, privacy constraints reduced ad performance because the industry’s performance depended on seeing more. Under a federated architecture, the relationship flips. If data stays local and the agent is trusted, users will share more context with the system that represents them: health constraints, financial boundaries, real-time location, schedule, family needs. That deeper context produces higher-value matching than surveillance ever could. Privacy stops being a tax. It becomes the enabler of premium inventory.
Whoever operates this infrastructure captures something unprecedented: not the attention graph, but the intent graph.
Not what users can be persuaded to want, but what they actually need. Search became a giant business because declared intent is more valuable than passive exposure. A personal agent holds something more valuable still: full context. Not a query, but the reason behind it. Not momentary desire, but constraints, timing, tradeoffs, and willingness to act.
Payment networks understood this dynamic in the physical economy. They built the rails through which commerce flows and participated in the value created. The operator of a federated matching layer in the agentic economy sits in an analogous position: essential infrastructure through which agents connect needs to solutions, buyers to sellers, and intent to execution.
The addressable market is not advertising. It is the portion of commerce that benefits from intelligent matching between supply and demand.
And the question is not whether ads will appear in chat interfaces.
The question is whether we will accept the old adversarial bargain, just rendered in a new font, or whether we will use personal intelligence to finally build a commercial system that feels like representation instead of surveillance.
VII. Who Builds This?
The question of who builds this infrastructure is more open than conventional analysis suggests. The assumption that data incumbents hold insurmountable advantages rests on a model of competition the agentic transition may invalidate.
Effective personal agents require not merely data but authorization: the user’s consent to synthesize understanding across domains. Authorization depends on trust. And trust is distributed quite differently than data.
Payment infrastructure providers function as trust intermediaries across commerce. They sit where agent decisions become economic reality. Consumer surveys consistently show payment providers among the most trusted institutions for data stewardship. This trust, built through decades of fiduciary responsibility, creates permission for the data integration personal intelligence requires. They have cross-domain visibility from transaction data. What they may lack is recognition that these assets position them for infrastructure far larger than current operations.
Technology platforms have AI capability but face trust deficits that may prove insurmountable. Their business models depend on advertising, creating structural conflicts with genuine user advocacy. Years of data practices prioritizing platform benefit over user welfare have compromised their position for the agentic era, where the question is not who captures attention but who earns authorization.
Other positions offer advantages. Device manufacturers control the hardware layer and have made privacy central to their brand. Financial institutions have rigorous frameworks for sensitive information. The federated architecture accommodates multiple orchestrators serving different domains, geographies, and use cases.
The protocol landscape is crystallizing: MCP for tool integration, AP2 and A2A for payment authorization, ACP for commerce execution. These solve how agents communicate and transact. They do not solve how agents understand. That intelligence layer is what remains missing. The question for any organization is not whether it becomes the sole winner. The question is whether it helps shape the infrastructure or waits until the architecture is designed without its input.
Ultimately, the dominant failure mode in agentic transitions is not technical. It is organizational. This layer is routinely misassigned: treated as a product surface, buried inside AI research, subordinated to advertising, or fragmented across platform teams. In each case, the result is the same. The system optimizes locally and fails structurally.
VIII. The Window
The window for preparation is not indefinite. Infrastructure not built becomes infrastructure adopted from others. Capabilities not developed become dependencies. Organizations that wait for clarity will find it arrived in the form of a landscape shaped by those who acted earlier.
What I have described is the shape of an opportunity, not its resolution. What remains is execution: the will to build infrastructure that does not yet exist for a market just emerging.
A note on concentration and governance: Personal AI infrastructure will consolidate. Network effects guarantee this. The architecture does not resist this dynamic; it channels it toward accountability. The question is not whether infrastructure concentrates but whether concentration occurs under governance maintaining user sovereignty. Cryptographic commitments and attestation chains enforce accountability independent of corporate goodwill. Regulatory frameworks provide external constraints. Concentration paired with verifiable commitment is acceptable. Concentration without accountability is not.
These second-order effects suggest the agentic transition is not a new channel or technology. It is a restructuring of how markets function. Organizations that recognize this early can position themselves. Those that treat it as incremental change will be structurally disadvantaged.
It is worth being explicit about what happens if this architecture is not built.
Agents will still advance. They will transact, schedule, and execute. But lacking epistemic completeness, they will optimize on what they can see: price, availability, and surface-level specifications. Brands will be reduced to interchangeable vectors. Loyalty will degrade because agents cannot honor history they do not possess. Trust will erode as agents make decisions that are locally correct but globally misaligned with the principal’s values.
The market consequence is not stagnation but collapse of differentiation. Margins compress. Experience becomes irrelevant because it cannot be rendered. Platforms compete on incentives rather than understanding. Users intervene manually more often, not less, because they cannot rely on representation. The promise of agency degenerates into automation theater.
This is not a hypothetical risk. It is the same dynamic that turned much of e-commerce into a race to the lowest visible price, except now applied to every category where agents intermediate choice. Without federated understanding, agentic commerce does not fail gracefully. It fails structurally.
IX. The Frameworks
The architectures described here are not presented as proprietary answers but as concrete instantiations of a broader requirement. Different organizations could implement materially different systems that satisfy the same constraints. The claim of this paper is not that any single framework must win, but that the class of architectures they represent must exist. LUCID and OPAL are offered to make the requirements explicit, critique-able, and buildable, not to imply inevitability of ownership.
LUCID (Learning Under Contained Inference Domains) defines the federated reasoning layer where organizations make available inference signals through mathematical embeddings rather than raw data. The framework specifies how understanding compounds across domains while ensuring privacy through cryptographic structure rather than policy promises.
Under LUCID, participants never share underlying data. They make patterns, correlations, and behavioral signals available as privacy-preserving mathematical representations that enable inference without exposure. A Universal Inference Oracle provides structured access to intelligence across the network, ensuring that each participant receives only the signals they are permitted to access. Privacy becomes a property of how computation occurs, not a promise requiring trust in corporate policy.
LUCID enables the impossible: competitors improving each other’s personalization without surrendering competitive intelligence. Netflix generates viewing patterns through normal user interaction. Spotify generates listening patterns the same way. Neither sees the other’s data. Both benefit when PAM-equipped users return with richer context. The mathematics of federated inference make this not merely possible but practical at scale.
OPAL (Orchestrated Personal Agentic Learning) extends this architecture to individual agency. Where LUCID describes how institutions can reason about individuals without possessing their data, OPAL describes how Personal Adaptive Models operate under individual sovereignty while leveraging federated infrastructure.
Each user is represented by a unique PAM: an AI instance trained specifically on them, learning continuously from their behavior, adapting to their circumstances, and evolving to understand them better than they understand themselves. The PAM synthesizes understanding from observation, behavior, and identity. It interacts with services through the same inference protocols institutions use under LUCID. But it operates under individual control rather than institutional custody.
OPAL specifies how PAMs learn from lived experience while remaining under individual governance. How they represent interests across domains. How they negotiate on behalf of their principals. How they maintain privacy while accessing federated intelligence. The personal agent becomes genuinely personal: a cognitive extension that serves individual interests rather than platform economics.
Together, LUCID and OPAL form a two-phase architecture. Phase One creates the federated intelligence layer: infrastructure enabling institutions to reason about individuals without possessing their data. Phase Two enables personal agents that leverage this infrastructure while operating under individual sovereignty. The same technology serves both the enterprise seeking to personalize and the individual seeking representation. Understanding flows in both directions. Control remains distributed.
I intend to publish both papers in full. They are specific enough to critique and concrete enough to start building. They represent my best current thinking on how personal superintelligence can be achieved at scale.
This essay is the first in a series exploring the agentic transition. Future installments will examine commerce, personalization, advertising, and personal assistants in greater depth.
The title of this essay refers to what I believe will be the final layer of mediation between human intention and digital fulfillment. Every previous interface, from the command line through the graphical interface through touch and voice, required humans to learn machine languages. The personal agent is the first interface that learns human language instead: not just words but patterns, preferences, contexts, and constraints. There is nowhere further to go. The interface disappears into understanding.
The race for the last interface is underway. The protocols are being written. The infrastructure is being built. The decisions are being made that will shape how humans and machines collaborate for the next generation.
About the Author
John Roa is a technologist, engineer, and designer who has spent more than two decades building, scaling, and transacting platform businesses as a founder and CEO. He has founded seven technology companies across design, data, and artificial intelligence, operating across product development, infrastructure, strategic partnerships, and corporate transactions.
His design and innovation consultancy was acquired by Salesforce, where he worked with senior leadership at global enterprises on platform strategy, experience systems, and large-scale transformation. More recently, he founded AnthologyAI and raised $30 million to explore personal intelligence and agent-mediated systems, engaging directly in capital formation, partnerships, and platform development.
Across roles as engineer, designer, executive, and dealmaker, his work has focused on how new infrastructure layers reshape markets, incentives, and organizational power. The frameworks described in this paper reflect that perspective, informed by almost a decade of research into personal superintelligence.
CITATIONS & SOURCES
[1] McKinsey $1-5T agentic commerce projection — McKinsey & Company, ‘The State of AI in Retail and Commerce,’ 2024
[2] AI-driven retail sales 1,200% increase — Salesforce Commerce Cloud Analytics, Q1 2025
[3] Google 60-organization protocol consortium — Google A2A Protocol Announcement, January 2025
[4] Anthropic MCP under Linux Foundation governance — Linux Foundation Agentic AI Foundation Press Release, 2025
[5] Amazon $25B Alexa investment — Business Insider, ‘Amazon’s Alexa Unit Lost $25 Billion,’ November 2022
[6] One in three voice assistant errors — Voicebot.ai Consumer Voice Assistant Survey, 2024
[7] 60-90 applications per average user — App Annie Mobile App Usage Report, 2024
[8] Google federated learning at scale — McMahan et al., ‘Communication-Efficient Learning from Decentralized Data,’ Google AI, 2017
[9] Flower Labs 15M device deployment — Flower Labs Technical Documentation, 2024
[10] SGX side-channel vulnerabilities — Van Bulck et al., ‘Foreshadow: Extracting Keys from Intel SGX,’ USENIX Security, 2018
[11] Payment provider trust levels — Edelman Trust Barometer, Financial Services Report, 2024
[12] Global digital advertising market ~$600B — eMarketer Global Digital Ad Spending Report, 2024
[13] Average display ad CTR below 1% — WordStream Industry Benchmarks, 2024